The gap between what AI promises security operations centers and what it actually delivers has now been measured. The numbers are not encouraging.
Record Spending, Underwhelming Results
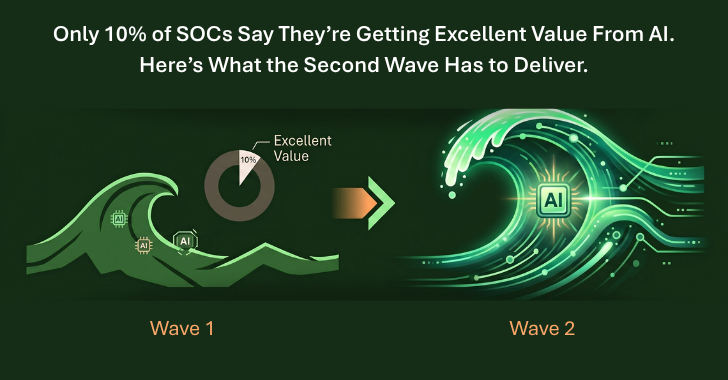
The SOC-CMM 2026 Maturity Report, published in May and based on survey data from roughly 200 SOCs collected between late January and mid-March 2026, produced the first objective benchmark on AI value inside security operations. The findings land hard. Only 10% of respondents said AI has delivered excellent value to their SOC. Another 19% reported good value. The remaining 71% - nearly three quarters of the field - reported some value or none at all.
That 71% figure deserves its own moment. These are not organizations that skipped the AI investment cycle. They are organizations that bought in, deployed, and stood up AI capabilities at the fastest adoption pace the security industry has recorded - and still found themselves underwhelmed. Eighteen months into meaningful AI deployment across the sector, that spread between adoption and perceived value is not a product problem or a vendor problem in isolation. It is a structural one.
The category grew in every direction simultaneously. Off-the-shelf large language models inside the SOC grew 55% year over year. AI co-pilots grew 145%. AI agents grew 118%. Supervised machine learning grew 96%. Customized LLMs grew 64%. Every metric points upward. The value perception data points almost entirely sideways.
What makes the SOC-CMM findings harder to dismiss is the uniformity across delivery models. Hybrid SOCs, in-house SOCs, and MSSP-run SOCs all reported nearly identical distributions of perceived AI value. If this were a configuration problem specific to one type of team, the data would break differently by delivery model. It does not. The pattern holds across region and sector too.
The Taker Problem
The report identifies three adoption archetypes. Takers deploy off-the-shelf AI without customization. Shapers customize what they buy. Builders train models against their own data. Sixty-five percent of SOCs surveyed fall into the taker category. Another 20% are shapers. Only 15% are builders.
The taker model is also the model reporting the least value. This is not coincidental.
Off-the-shelf AI tools arrive pre-trained on generalized datasets and pre-configured for generalized workflows. A SOC with specific detection logic, a specific threat profile, a specific analyst team structure, and years of accumulated institutional context gets a tool that knows none of that. It answers questions based on someone else’s environment. Taker-model adoption produces taker-model results: functional in isolation, blind to everything that makes a specific SOC actually run.
Shaper and builder adoption requires something most organizations find uncomfortable to admit they lack - enough operational maturity to know what to customize and why. That admission connects directly to the report’s third major finding. Among the SOC improvement challenges that grew year over year, lack of best practices increased by 17% and complexity of increasing maturity increased by 11%. Every other challenge category, including lack of budget and lack of management support, dropped. SOC teams are not telling the survey they need more money or more executive buy-in. They are telling it they do not know what they are supposed to be doing with the AI they already purchased. That is a different problem, and it does not respond to the same solutions.
Five Assistants, Zero Coordination
The first wave of AI in security operations arrived as features layered onto existing products. SIEMs gained AI triage. EDR platforms gained AI-assisted investigation. SOAR platforms gained AI playbook generation. Ticketing systems gained AI summarization. Each capability was real. Each worked within its own perimeter.
None of them shared context with the others.
The practical result is that an analyst working a live incident now has five AI assistants running in parallel, each operating with a partial picture. The triage agent in the SIEM does not know what the detection engineer silenced last week. The threat hunting agent in the EDR does not know what the threat intelligence team flagged earlier that morning. The summarization agent in the ticketing tool does not know what the investigation uncovered two hops back in the evidence chain. Each agent accelerates its own slice of the workflow. The handoffs between those slices - which is where the majority of SOC time is spent and where the majority of SOC value either gets created or lost - remain entirely unaddressed.
This fragmentation creates a specific and well-documented frustration pattern. Analysts describe completing individual tasks faster while the overall workflow remains as fractured as it was before. They describe being asked to learn five separate agent interfaces, each with its own input logic and output format, while the underlying problem - that the SOC functions as a chain of disconnected processes rather than a coherent operation - persists underneath all of it. Speed at the task level does not fix friction at the workflow level. The SOC-CMM data reflects exactly this: tools that perform, operations that don’t.
The first wave solved for features. The second wave will need to solve for continuity. An AI capability that can operate across the full alert-to-resolution workflow - carrying context from detection through triage through investigation through response without dropping it at each tool boundary - addresses a different problem than any individual feature does. That is the gap that the 71% are feeling even if they are not always describing it in those terms.
What the Second Wave Actually Has to Do
The maturity gap the report names is not primarily a technology shortfall. It is a knowledge shortfall. SOCs that cannot articulate what they want AI to do for them will not be able to configure shapers or train builders. They will remain takers, and they will continue to report the value outcomes takers report.
This creates an uncomfortable dependency. The second wave of AI SOC tools has to do two things at once: deliver better cross-context coordination at the technical layer, and actively guide teams toward the operational practices that make customization possible. A platform that only improves the underlying model without addressing how teams engage with it will produce a second round of adoption without a second round of value.
The specific challenges the SOC-CMM data identifies - best practices deficit up 17%, maturity complexity up 11% - suggest that the industry’s next product question is not what can AI do in the SOC, but what does a SOC need to look like before AI stops underperforming in it. The two questions are connected. Teams operating with undefined workflows, inconsistent detection logic, and no documented escalation paths give AI tools nothing coherent to accelerate.
The 10% reporting excellent value are presumably not reporting it by accident. The SOC-CMM report does not break down what differentiates that cohort at the operational level, which is itself an open question worth following as the 2026 data matures.